祝贺实验室博士后颜鲲合作论文被计算机视觉顶会CVPR接收
近日,北京大学智能计算与感知实验实验室与微软亚洲研究院合作的“Minimizing Labeled, Maximizing Unlabeled: An Image-Driven Approach for Video Instance Segmentation”论文被计算机视觉领域三大顶会之一的CVPR 2025接收,实验室博士后颜鲲为共同通讯作者。
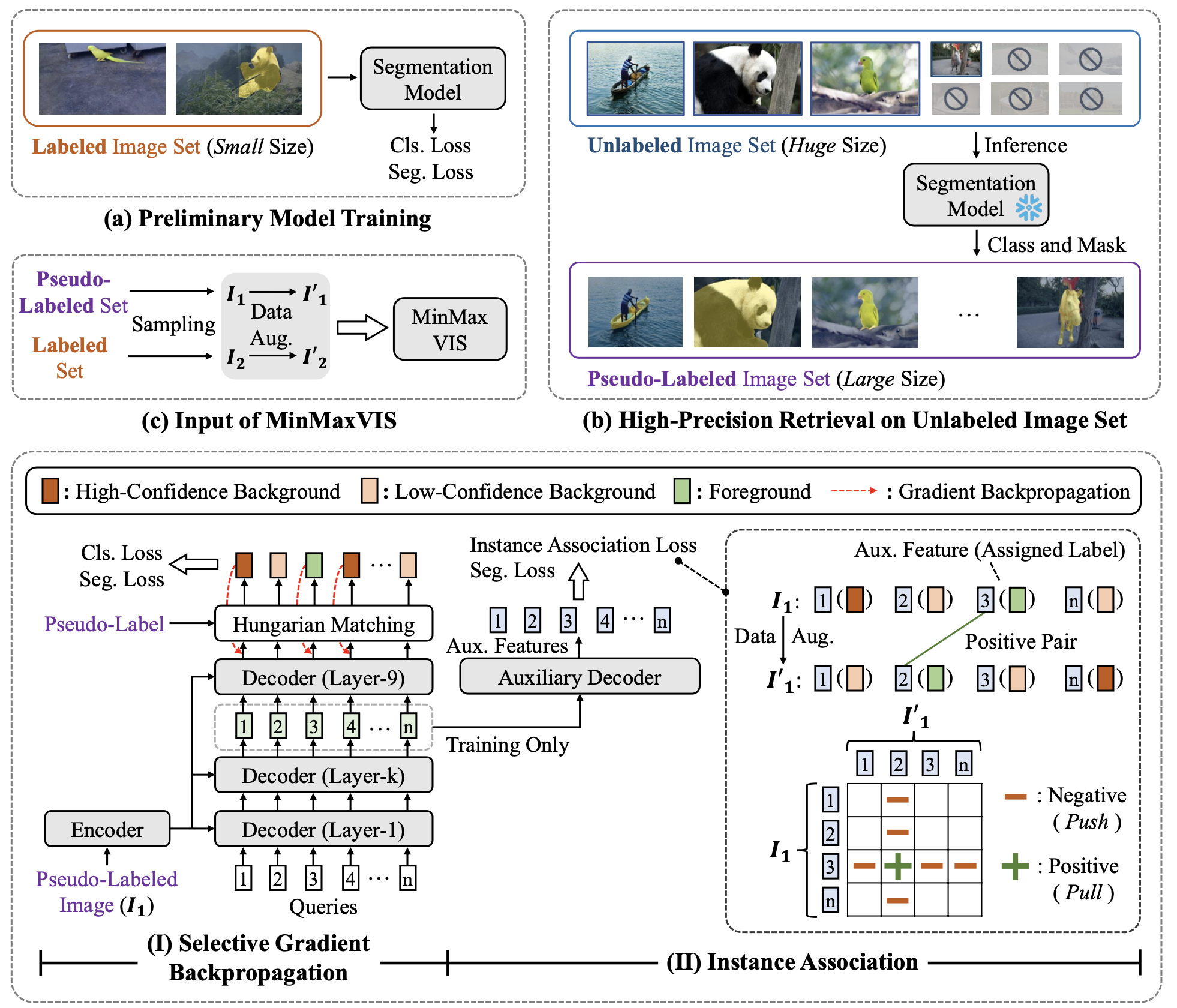
传统的视频实例分割 (VIS) 模型依赖于大量的每帧视频注释,这既耗时又昂贵。本文提出了 Min-MaxVIS,这是一种新颖的 VIS 框架,它通过利用来自目标域的一小组标记图像以及大量通用域的未标记图像来减少对完全标记的视频数据集的依赖。Min-MaxVIS 分三个阶段运行:首先,在来自目标域的少量标注数据上训练初步分割模型;然后,该模型从大量无标注集中检索目标域相关实例以构建高质量的伪标记集。最后,模型在标注和无标注数据的组合上训练MinMaxVIS,并解决伪标签中的噪声和跨帧实例关联等挑战。为了模拟对象连续性,对静态图像进行数据增强以创建成对的帧,从而使MinMaxVIS能够有效地捕获实例关联性。MinMaxVIS 的表现优于之前的图像驱动方法 MinVIS,在显著减少标注数据的情况下实现了更高的mAP分数。例如,使用Swin-L主干的 MinMaxVIS仅使用2%的标注数据和来自SA-1B的额外未标注图像在YouTube-VIS 2019上获得了 62.2 mAP。这比使用在YouTube-VIS 2019所有标注数据下上训练的MinVIS高出0.6 mAP。
CVPR是计算机学科普遍认可的计算机视觉领域顶级国际会议,被中国计算机学会(CCF)列为A类会议,其录用论文指引着计算机视觉领域未来的研究方向,今年有效投稿数量为13008,最终接收论文数量为2878,录用率为22.1%左右。根据权威的Google Scholar Citation统计,当前CVPR排在所有学科目录第2位(Nature第1位),排在工程与计算机学科榜单第1位。